Cacheback: Speculative Decoding With Nothing But Cache
Nov 4, 2025·
·
0 min read
Zhiyao Ma
Equal contribution
,
In Gim
Equal contribution
,
Lin Zhong
Abstract
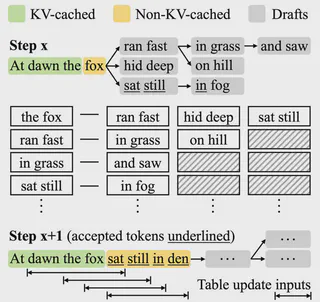
We present Cacheback Decoding, a training-free and model-agnostic speculative decoding method that exploits the locality in language to accelerate Large Language Model (LLM) inference.Cacheback leverages only Least Recently Used (LRU) cache tables of token n-grams to generate draft sequences.Cacheback achieves state-of-the-art performance among comparable methods despite its minimalist design, and its simplicity allows easy integration into existing systems.Cacheback also shows potential for fast adaptation to new domains.
Type
Publication
In The 2025 Conference on Empirical Methods in Natural Language Processing